webFrame
The execution layer for high-performance sovereign AI
Optimize and accelerate model execution across every device you own—without cloud dependency.
webFrame is the intelligent execution engine behind model performance on the webAI Platform. It optimizes inference for supported models and hardware configurations, simplifying complex tasks like quantization and batching. The result is faster, more efficient AI that operates entirely within your infrastructure.
Adaptive Optimization
Automatically tunes models for each device's compute profile to maximize throughput and minimize latency.
End-to-End Efficiency
Proprietary quantization and batching improve model throughput and enable seamless distribution across devices.
Hardware Flexibility
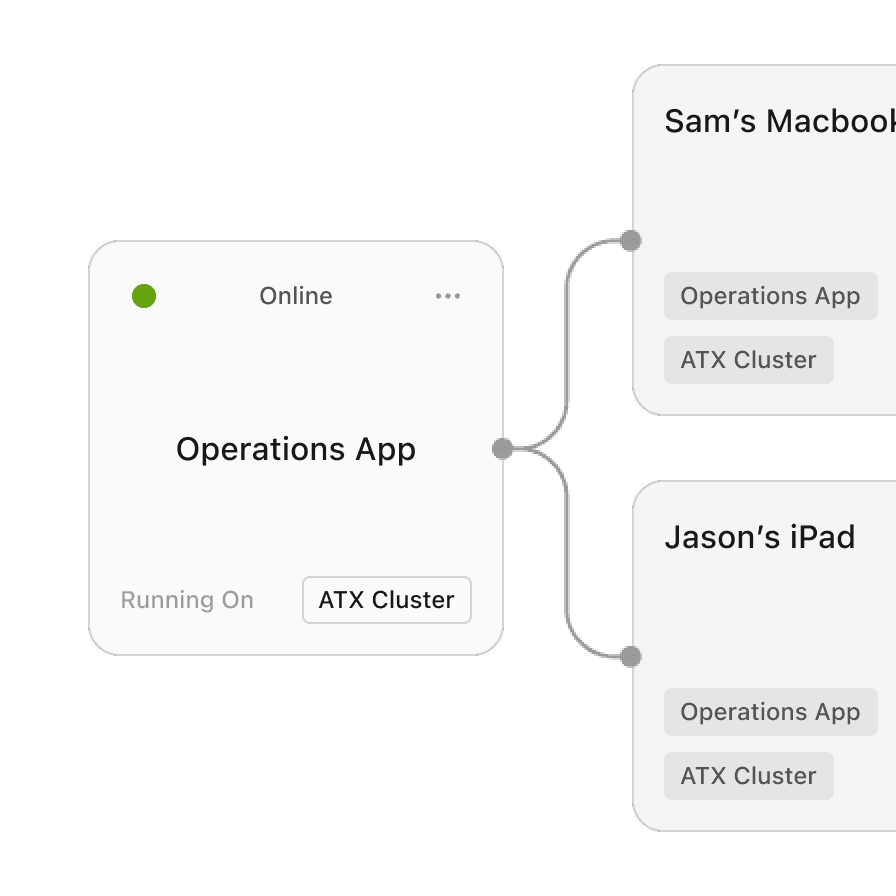
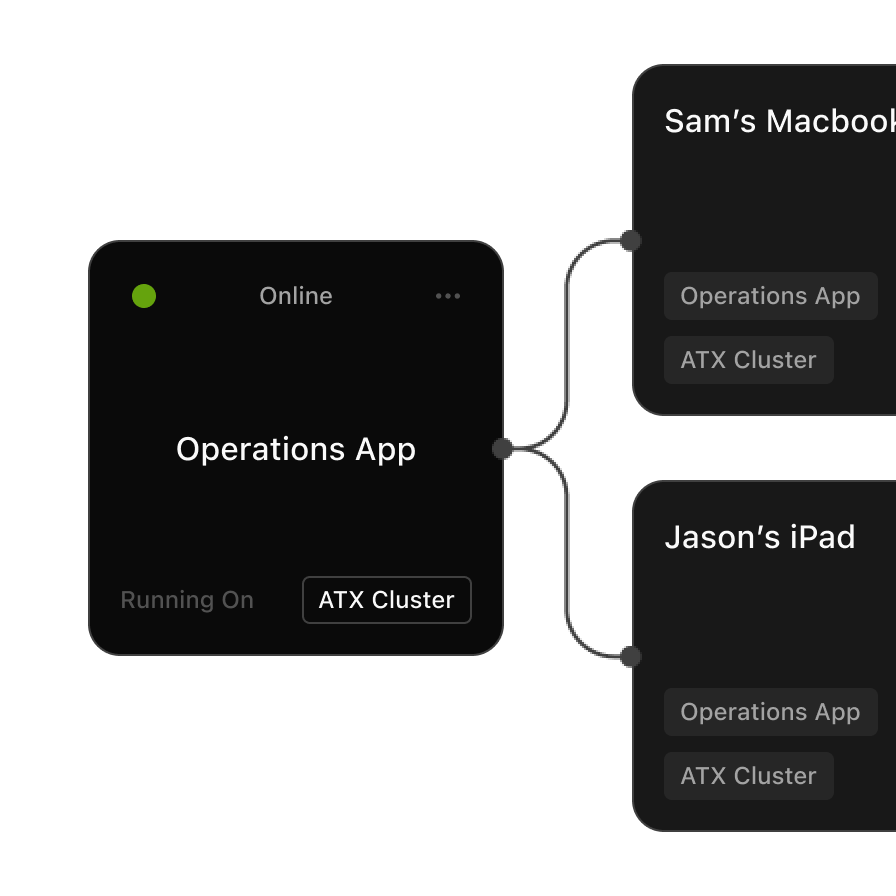
Runs seamlessly across consumer-grade Macs and enterprise clusters without reconfiguration.
Local Execution
Keeps all inference and training inside your environment—no external dependencies or data exposure.
Accuracy Preserved
Maintains up to 99.5% accuracy while reducing model size for edge and on-device deployment.
Inside webFrame the intelligent optimization stack that makes private AI performant at scale.
Inside webFrame the intelligent optimization stack that makes private AI performant at scale.
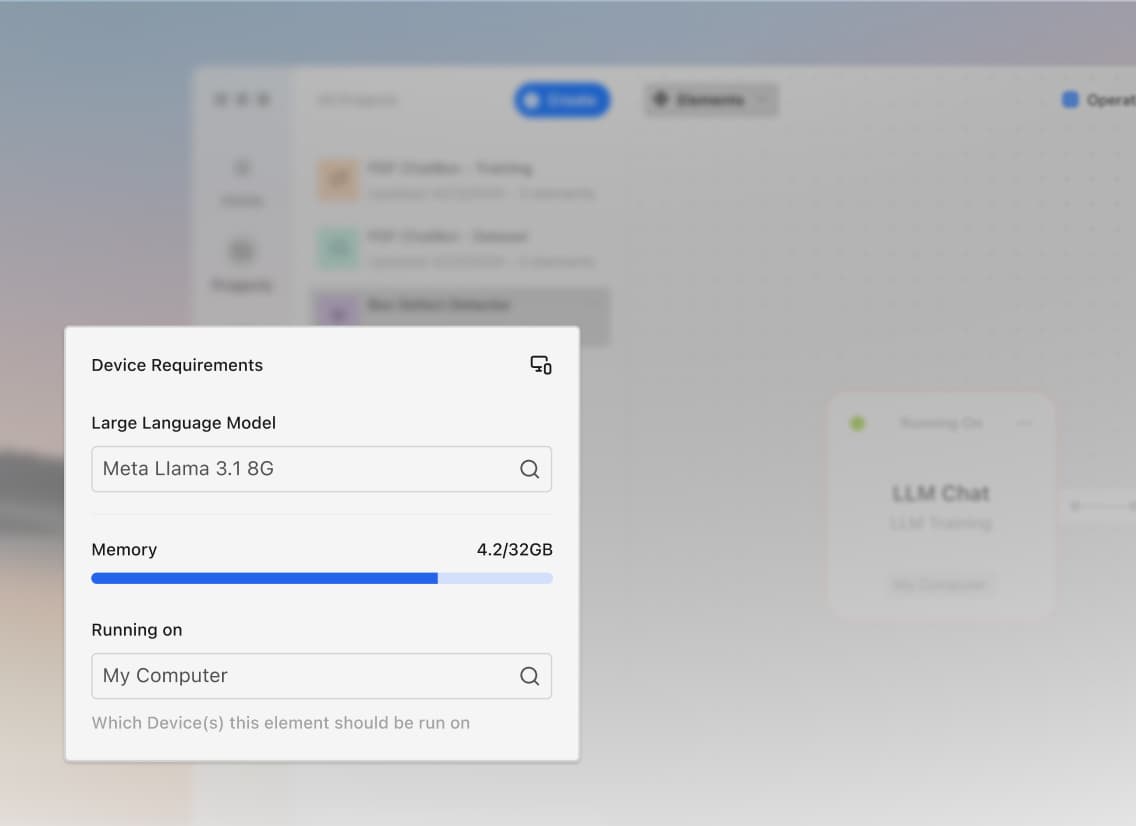
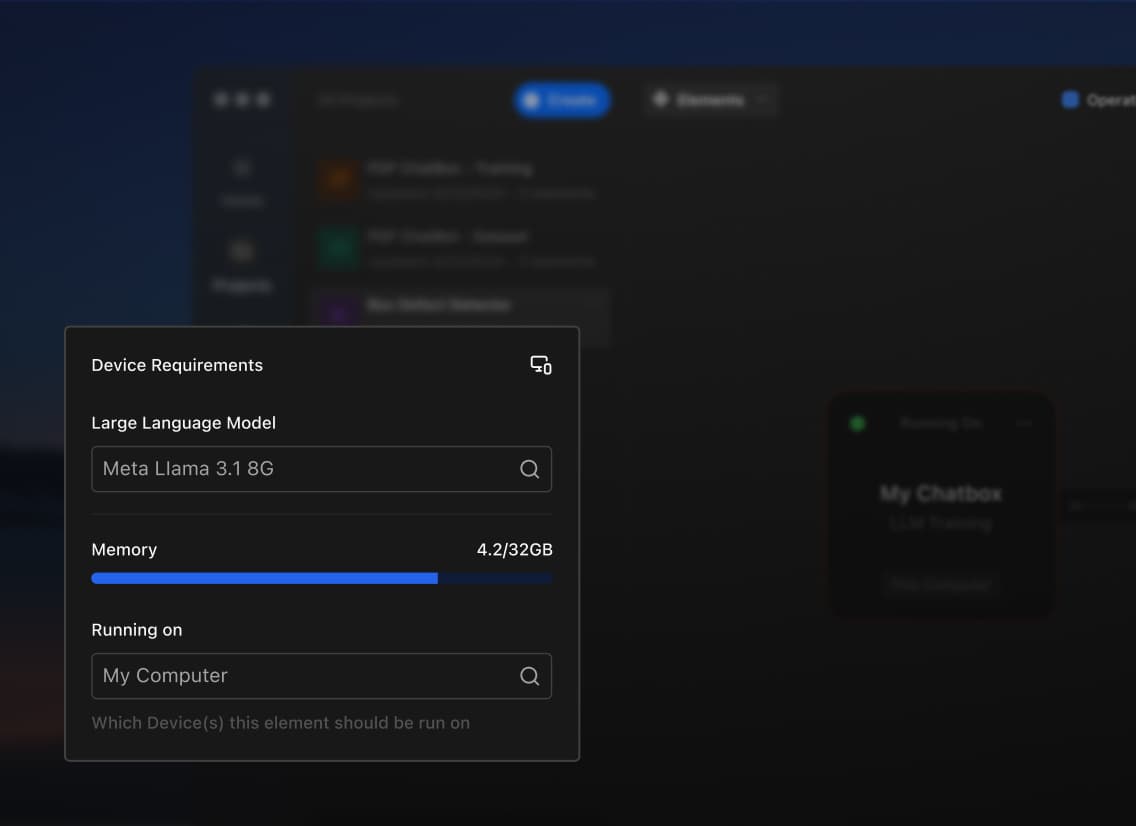
Detects device capabilities at runtime and adapts execution strategy automatically.
The webAI Platform
webAI brings every layer of sovereign AI into one system. From model creation to deployment and orchestration, explore how the pieces fit together to power custom, private AI across your organization.